Speech is the most natural way of communicating for human beings. Systems of spoken language had developed long before the most primitive attempts at writing were even made. While the gift of language in general and speech in particular comes easy to people, the science has been struggling to make machines produce speech that would sound as natural as possible.
The goal of speech synthesis, also known as text-to-speech, is to convert written texts into spoken utterances. Speech synthesis finds application in many areas of our everyday life, ranging from announcements at train stations to voice assistants in call centers.
Given we have the recordings of a person speaking, we may recreate their voice to generate arbitrary utterances. This is a unique opportunity for people who have lost their voices due to some medical issues. Text-to-speech can also be used to reconstruct the voice of deceased loved ones. Sometimes hearing reassuring things in the voice of a late beloved may help to process the grief and ease the pain.
...Or we can build our own voice right now just for fun!
Listen to some things I never said... (but then I did)
Here are several samples of synthetically created utterances along with the references, i.e. me pronouncing the same sentences. Speech samples under "Unit selection" header are generated by an open-source framework Festival using the custom voice I've built on my own speech data (around 400 recordings of me reading prompts from the CMU ARCTIC dataset.). Samples under "SV2TTS" are created with the help of SV2TTS, a real-time voice cloning framework that uses pre-trained deep neural networks.
NB: All wave files have the following characteristics: 16kHz sampling rate, 1 channel, 16-bit.
Unit selection
SV2TTS
Reference speech
1. "Happiness isn't in the having. It's in just being. It's in just saying it."
Unit selection
SV2TTS
Reference speech
2. "Maturity is a bitter disappointment for which no remedy exists, unless laughter could be said to remedy anything."
Unit selection
SV2TTS
Reference speech
3. "If you don't know, the thing to do is not to get scared, but to learn."
Unit selection
SV2TTS
Reference speech
4. "Enjoy the little things in life, for one day you'll look back and realize they were big things."
Unit selection
SV2TTS
Reference speech
5. "Fear is the path to the dark side. Fear leads to anger. Anger leads to hate. Hate leads to suffering."
Unit selection
SV2TTS
Reference speech
6. "He was my North, my South, my East and West, My working week and my Sunday rest, My noon, my midnight, my talk, my song; I thought that love would last forever: I was wrong."
You reap what you sow
Or how machine learning practitioners like to say: garbage in - garbage out. This statement stays true when we deal with speech synthesis as well. While TTS systems based on deep neural networks may benefit from such a concept as transfer learning, i.e. utilizing the knowledge gained by a model while being trained on different data or task, and in some cases may reproduce someone's voice with just a few samples, unit selection (concatenative) speech synthesis heavily rely on the data it is built with.
As the name suggests, concatenative speech synthesizer selects pre-recorded units of speech and concatenates them to form a new utterance. It's obvious that the quality of generated speech will depend on how carefully the dataset was designed. To that end, there are several criteria that need to be considered:
Phonemic coverage. While creating a script, it's important to design a script in a way that the final recording are phonetically balanced.
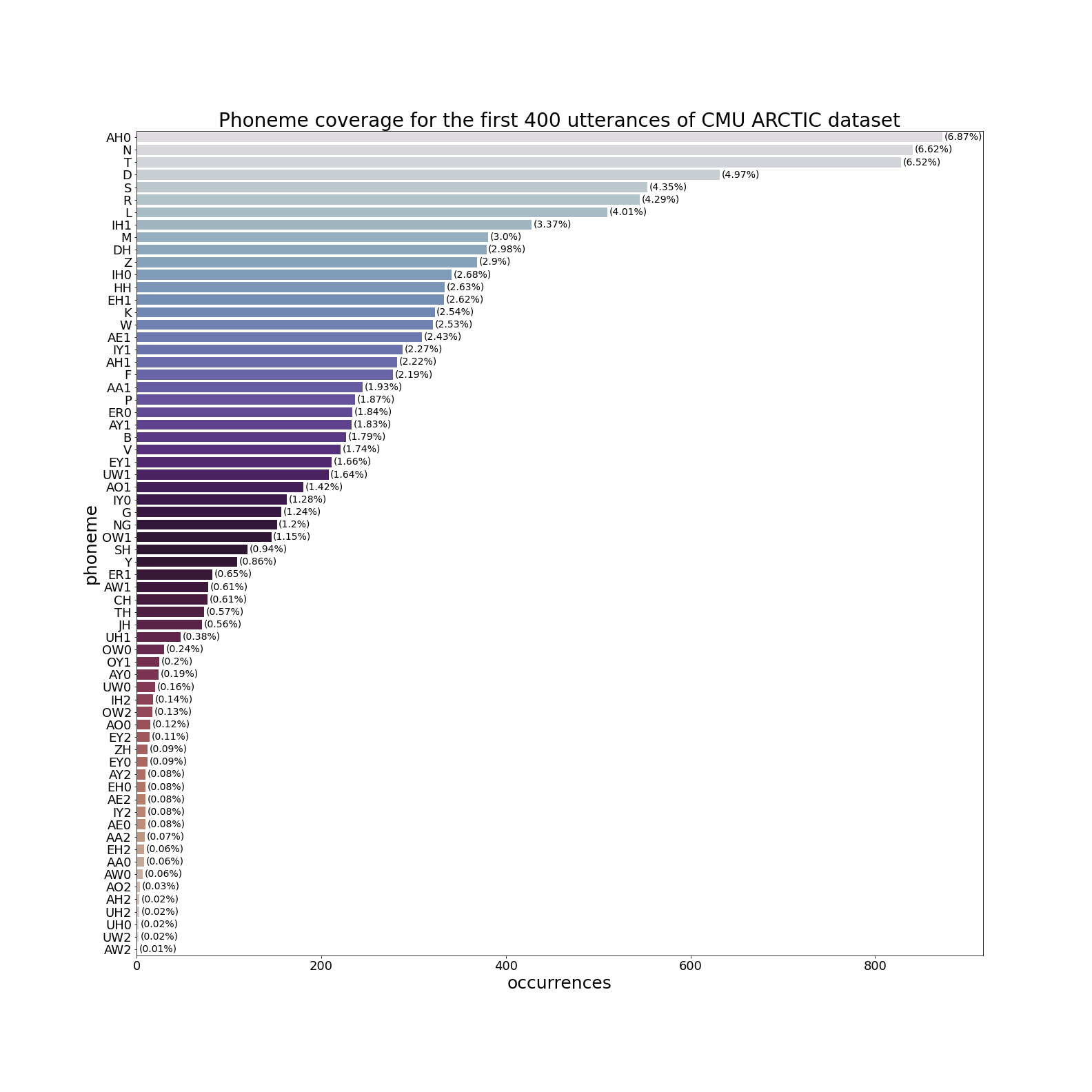
The diagram below shows the distribution of individual phonemes in the dataset that I recorded for building a custom unit selection voice (NB: this is CMU phonetic notation). As we can see, some phonemes are severely underrepresented, especially vowels with the secondary stress (the ones with a digit 2).
Diphone (triphone) coverage. It may seem counterintuitive to a non-phonetician that the same phoneme is not quite the same depending on the context it occurs in. /k/ in cat, puncture, and look are not the same. Different realizations of the same phoneme are called allophones. While using them interchangeably will probably not cause problems at understanding, the naturalness of speech will be lost. Thus, in case of unit selection speech synthesis it's crucial to provide as many samples of a phoneme in as many phonemic contexts as possible.
Prosodic coverage. Prosody basically deals with everything in phonetics that is above individual phones: intonation, rhythm, stress, etc. Therefore, it's vital to make sure that the dataset is prosodically balanced: there is a sufficient amount of declarative, exclamatory, interrogative and imperative sentences; the style of delivery by the speaker is consistent in terms of rhythm and emotions; etc.
One of the main obstacles for those who are learning Russian is the need to map the pronunciation of Cyrillic characters to correct phonemes. Converting Russian words into International Phonetic Alphabet may help, but is this task of grapheme-to-phoneme conversion as simple as it seems?
It’s not uncommon for data scientists to work on imabalnced data, i.e. such data where classes are not uniformly distributed and one or two classes present a vast majority. Actually, most of classification data is usually imbalanced. To name but a few: medical data to diagnose a condition, fraud detection data, churn client data etc.
The more companies are interested in using machine learning and big data in their work, the more they care about the interpretability of the models. This is understandable: asking questions and looking for explanations is human.
We want to know not only "What's the prediction?", but "Why so?" as well. Thus, interpretation of ML models is important and helps us to: