
Handling imbalanced data with resampling
Published:
It's not uncommon for data scientists to work on imabalnced data, i.e. such data where classes are not uniformly distributed and one or two classes present a vast majority. Actually, most of classification data is usually imbalanced. To name but a few: medical data to diagnose a condition, fraud detection data, churn client data etc.
The problem here is that machine learning algorithms may overfit on the majority class and totally ignore the minor classes. At the same time, it is the minority class samples (a rare disease or a fraudulent transaction) that we are interested in detecting! One of the ways to overcome the problem of imbalanced data is resampling, i.e. changing the number of samples in the different classes. There are at least three ways to resample data:
- Oversampling: adding the minory class samples.
- Undersampling: deleting the majority class samples.
- Combination of oversampling and udnersampling.
In this post we will examine some popular resampling techniques as well as discover why Accuracy is not always a good evaluation metric.
First, we will look at different resampling methods in action and plot the results. Afterwards we are going to create a classification model on imbalanced data with and without resampling.
Resampling on synthetic data
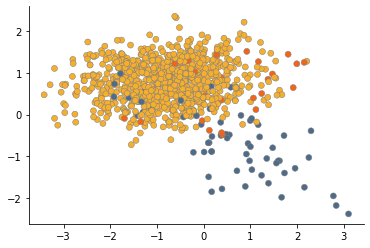
Generate imbalanced data
Let's create some imbalanced data to demonstrate the differene between resampling methods.
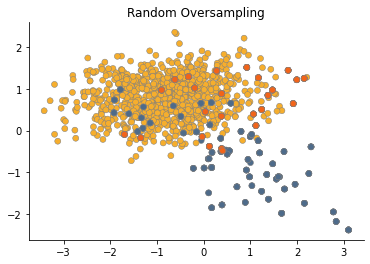
Random oversampling
First, let's try the most naive approach - random oversampling. This will create a duplicate samples of a minor class.
SMOTE
A more advanced method - SMOTE (Synthetic Minority Oversampling Technique) - doesn't just duplicate an existing sample. SMOTE generates a new sample considering its k neareast-neighbors.
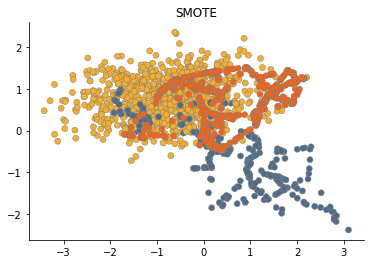
The plot shows that SMOTE generates many "noisy" samples that are placed between the outliers and the true minor samples.
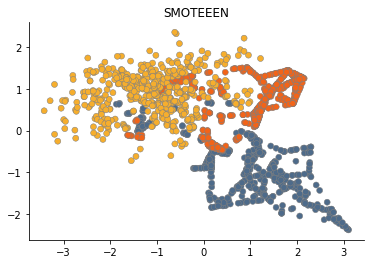
SMOTEEN
To solve this problem, one may use any of "cleaning" undersampling methods. For instance, SMOTEEN (SMOTE + Edited Nearest Neighbours) generates new samples as a vanila SMOTE, but then deletes those which class is different from the k-nearest neighbours' class.
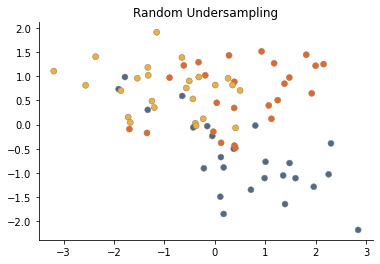
Random undersampling
The plot below shows how random undersampling, i.e. random deletion of major class samples, work.
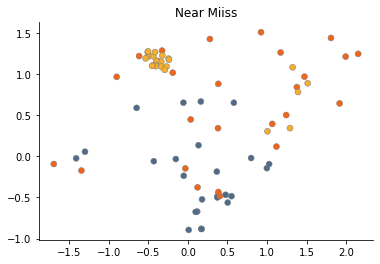
Near Miss
Another undersampling method - Near Miss - deletes the major class samples for which the average distance to the N closest samples of the minor class is the smallest.
Resampling on real data
Now that we have a basic idea how different resampling approaches work, let's try to apply this knowledge in a real classification task. We are provided with the information about the results of a bank marketing campaign. Our task is to predict whether the client signs a term deposit.
Let's get the data and look at the distribution of the target variable.
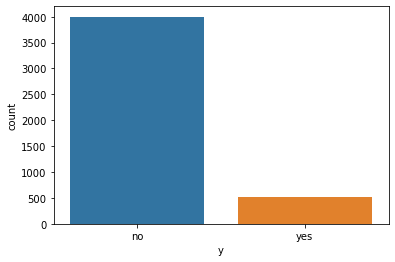
It's clear that the data is imbalanced. There is much more information on people who declined to sign a deposit. To process the data further, let's transform some categorical features that need to be encoded.
Some other categorical variables will be encode with the help of ohe-hot encoding, i.e. each category of a feature will be now represented as a separate column.
Index(['age', 'education', 'default', 'balance', 'housing', 'loan', 'day', 'month', 'duration', 'campaign', 'pdays', 'previous', 'y', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'job_unknown', 'marital_married', 'marital_single'], dtype='object')
Let's separate the target variable from the rest of the feautures and create train and test sets. NB: Don't forget to use stratification when splitting the data into train and test. This will help to preserve the same class distribution as in the whole dataset.
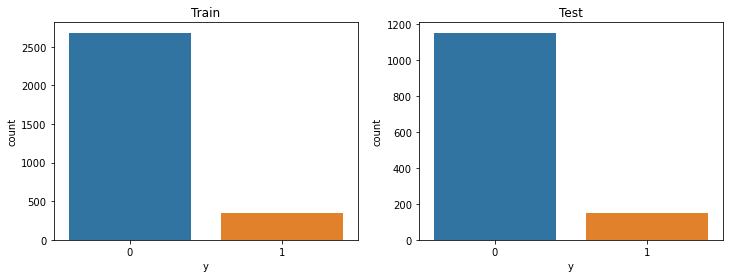
Baseline: logistic regression on imbalanced dataset
Accuracy: 0.891
Wow great! 89% of accurate predictions with a simple model. But should we really trust this metric? Let's take a closer look at the performance of the classifier. A confusion matrix and a classification report will be quite handy in this case.
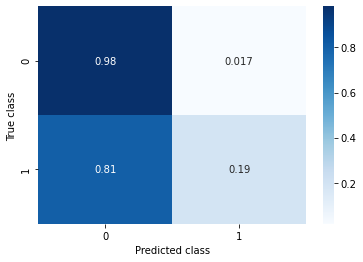
Accuracy: 0.891
Recall: 0.192
Here it is! Recall for class 1 - the class we are actually interested in - is lower 20%. What does that mean?
Well, let's imagine that this classifier is used in production, i.e. the marketing dept is relying on the model to identify people that would likely sign a term deposit. Do you see it now? We have effectively missed 80% of the potential clients!
In order to minimize the number of such misses, we need to pay closer attention to recall rather than relying solely on accuracy.
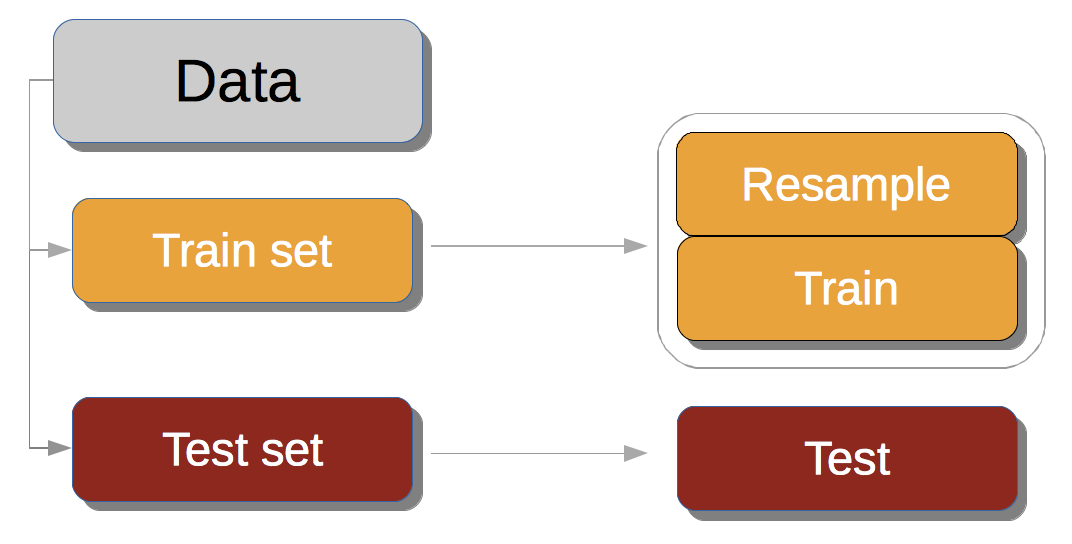
The right way to use resampling:
- Split your data in train and test sets.
- Resample only the train set!
- Estimate the classification quality on the test set.
Violating this procedure may lead to an inadequate evaluation results. For example, if you first resample and split your data, the same sample may be found in both train and test sets. This would be a leakage of data - the model is tested on an object that was present in the train.
Oversampling
Random Oversampling
This approach simply duplicates existing samples of a minor class.
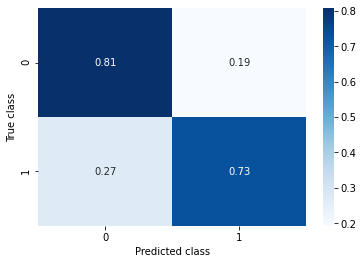
Accuracy: 0.798
Recall: 0.728
SMOTE
SMOTE generates new minor class samples by means of interpolation.
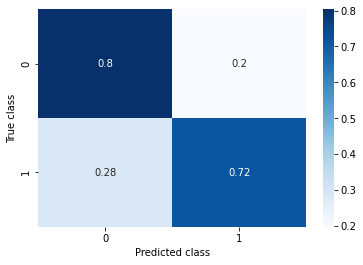
Accuracy: 0.793
Recall: 0.715
Undersampling
Random Undersampling
Randomly delete some objects of major class.
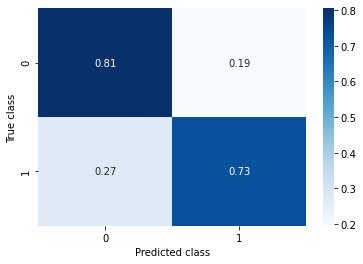
Accuracy: 0.796
Recall: 0.728
Combination of oversampling и undersampling
SMOTE with Tomek's links:
- Generate new samples with SMOTE.
- Delete objects that create Tomek's link. A Tomek’s link exist if the two samples are the nearest neighbors of each other.
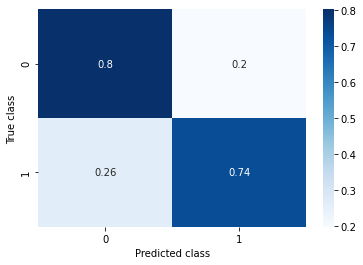
Accuracy: 0.795
Recall: 0.735
Wrapping up
In this post, we have presented a few approaches to handle imbalanced data. We've seen how misleading can be such a metric as Accuracy in case of class imbalance. We've also given a closer look to differences between some resampling techniques.